I’ll ask you to add ~30K useless hashtable lookups for each request in your application. Even if 40 requests are running concurrently (30 * 40 = 1.2M), the performance price would not be visible to a naked eye on modern servers.
Would that argument convince you to waste power you pay for? I hope not.
Why could that happen in real life?
The one we look at today – lack of respect to code mainstream execution path.
A pure function with single argument is called almost all the time with the same value. It looks as an obvious candidate to have the result cached. To make the story a bit more intriguing – cache is already in place.
Sitecore.Security.AccessControl.AccessRight ships a set of well-known access rights (f.e. ItemRead, ItemWrite). The right is built from name via a set of ‘proxy‘ classes:
AccessControl.AccessRightManager– legacy static manager called firstAbstractions.BaseAccessRightManager– call is redirected to the abstractionAccessRightProvider– locates access right by name
ConfigAccessRightProvider is the default implementation of AccessRightProvider with Hashtable (name -> AccessRight) storing all known access rights mentioned in Sitecore.config:
<accessRights defaultProvider="config">
<providers>
<clear />
<add name="config" type="Sitecore.Security.AccessControl.ConfigAccessRightProvider, Sitecore.Kernel" configRoot="accessRights" />
</providers>
<rights defaultType="Sitecore.Security.AccessControl.AccessRight, Sitecore.Kernel">
<add name="field:read" comment="Read right for fields." title="Field Read" />
<add name="field:write" comment="Write right for fields." title="Field Write" modifiesData="true" />
<add name="item:read" comment="Read right for items." title="Read" />
Since CD servers never modify items on their own, rules that modify data are rarely touched. So that a major pile of hashtable lookups inside AccessRightProvider likely targets *:read rules.
Assumption: CD servers have dominant read workload
The assumption can be verified by building the statistics for accessRightName requests:
public class ConfigAccessRightProviderEx : ConfigAccessRightProvider
{
private readonly ConcurrentDictionary<string, int> _byName = new ConcurrentDictionary<string, int>();
private int hits;
public override AccessRight GetAccessRight(string accessRightName)
{
_byName.AddOrUpdate(accessRightName, s => 1, (s, i) => ++i);
Interlocked.Increment(ref hits);
return base.GetAccessRight(accessRightName);
}
}
90% of calls on Content Delivery role aims item:read as predicted:

item:read gets ~80K calls for startup + ~30K each page request in a local sandbox.
Optimizing for straightforward scenario
Since 9 out of 10 calls would request item:read, we could return the value straightaway without doing a hashtable lookup:
public class ConfigAccessRightProviderEx : ConfigAccessRightProvider
{
public new virtual void RegisterAccessRight(string accessRightName, AccessRight accessRight)
{
base.RegisterAccessRight(accessRightName, accessRight);
}
}
public class SingleEntryCacheAccessRightProvider : ConfigAccessRightProviderEx
{
private AccessRight _read;
public override void RegisterAccessRight(string accessRightName, AccessRight accessRight)
{
base.RegisterAccessRight(accessRightName, accessRight);
if (accessRight.Name == "item:read")
{
_read = accessRight;
}
}
public override AccessRight GetAccessRight(string accessRightName)
{
if (string.Equals(_read.Name, accessRightName, System.StringComparison.Ordinal))
{
return _read;
}
return base.GetAccessRight(accessRightName);
}
}
All the AccessRights known to the system could be copied from Sitecore config; an alternative is to fetch them from the memory snapshot:
private static void SaveAccessRights()
{
using (DataTarget dataTarget = DataTarget.LoadCrashDump(snapshot))
{
ClrInfo runtimeInfo = dataTarget.ClrVersions[0];
ClrRuntime runtime = runtimeInfo.CreateRuntime();
var accessRightType = runtime.Heap.GetTypeByName(typeof(Sitecore.Security.AccessControl.AccessRight).FullName);
var accessRights = from o in runtime.Heap.EnumerateObjects()
where o.Type?.MetadataToken == accessRightType.MetadataToken
let name = o.GetStringField("_name")
where !string.IsNullOrEmpty(name)
let accessRight = new AccessRight(name)
select accessRight;
var allKeys = accessRights.ToArray();
var content = JsonConvert.SerializeObject(allKeys);
File.WriteAllText(storeTo, content);
}
}
public static AccessRight[] ReadAccessRights()
{
var content = File.ReadAllText(storeTo);
return JsonConvert.DeserializeObject<AccessRight[]>(content);
}
The test code should simulate similar to real-life workload (90% hits for item:read and 10% to others):
public class AccessRightLocating
{
private const int N = (70 * 1000) + (40 * 10 * 1000);
private readonly ConfigAccessRightProviderEx stock = new ConfigAccessRightProviderEx();
private readonly ConfigAccessRightProviderEx improved = new SingleEntryCacheAccessRightProvider();
private readonly string[] accessPattern;
public AccessRightLocating()
{
var accessRights = Program.ReadAccessRights();
string otherAccessRightName = null;
string readAccessRightName = null;
foreach (var accessRight in accessRights)
{
stock.RegisterAccessRight(accessRight.Name, accessRight);
improved.RegisterAccessRight(accessRight.Name, accessRight);
if (readAccessRightName is null && accessRight.Name == "item:read")
{
readAccessRightName = accessRight.Name;
}
else if (otherAccessRightName is null && accessRight.Name == "item:write")
{
otherAccessRightName = accessRight.Name;
}
}
accessPattern = Enumerable
.Repeat(readAccessRightName, count: 6)
.Concat(new[] { otherAccessRightName })
.Concat(Enumerable.Repeat(readAccessRightName, count: 3))
.ToArray();
}
[Benchmark(Baseline = true)]
public void Stock()
{
for (int i = 0; i < N; i++)
{
var toRead = accessPattern[i % accessPattern.Length];
var restored = stock.GetAccessRight(toRead);
}
}
[Benchmark]
public void Improved()
{
for (int i = 0; i < N; i++)
{
var toRead = accessPattern[i % accessPattern.Length];
var restored = improved.GetAccessRight(toRead);
}
}
}
Benchmark.NET test proves the assumption with astonishing results – over 3x speedup:
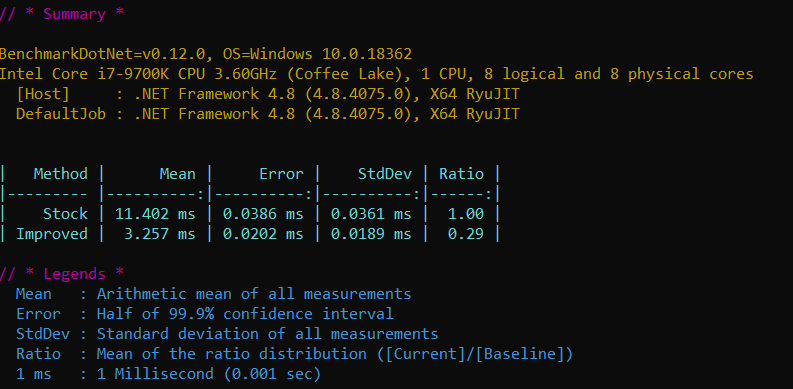
Conclusion
The performance was improved over 3.4 times by bringing respect for the mainstream scenario –item:read operation. Being a minor win on a single-operation scale, it gets noticeable as number of invocations grows.

One thought on “Performance crime: no respect for mainstream flow”